Set of tools to store relational databases in a standard archival format.

Desktop application to store database to archival format, validate it and browse the content.
Download
Web application to browse and search the content of multiple large archived databases.
Read more or Get support
A command-line tool and development library for automation and systems integration.
Read more or Get support
Desktop application to store database to archival format, validate it and browse the content.
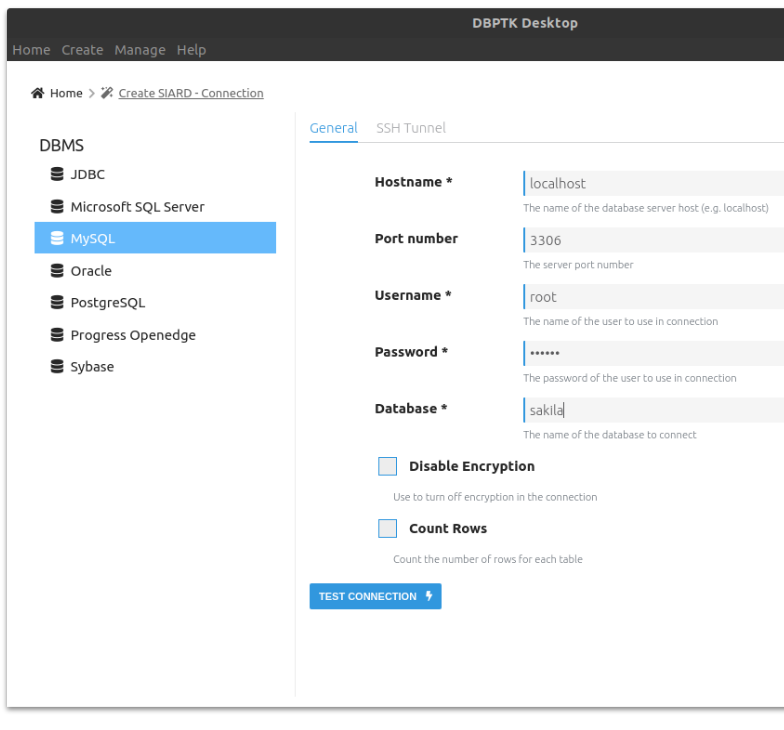
Download for Windows, MacOS or LinuxConnect to a local or remote database engine and store all content in an standard archival format such as SIARD.
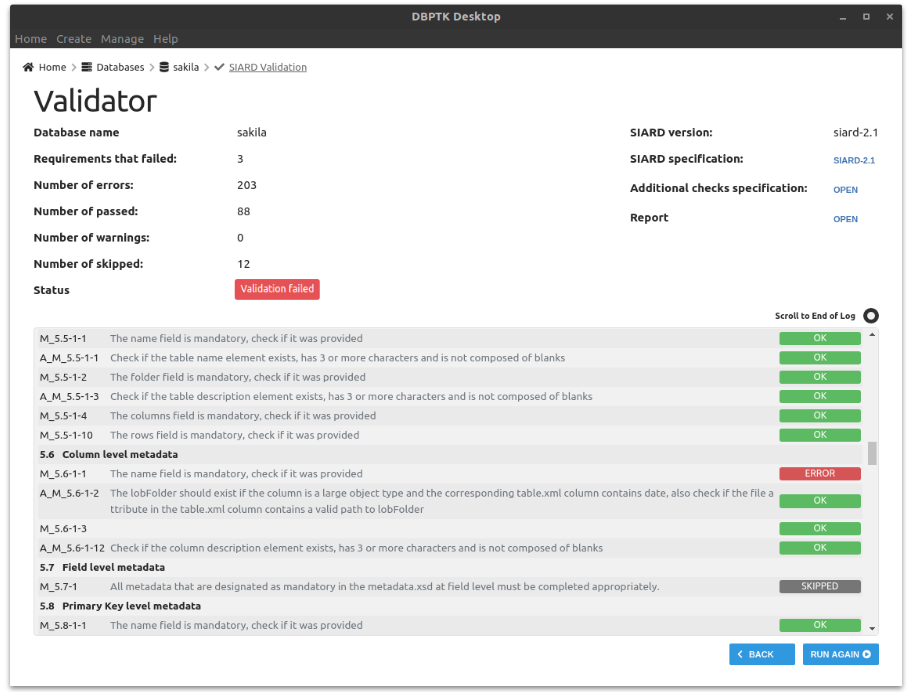
Validate SIARD against specification plus many additional checks for a thorough validation.
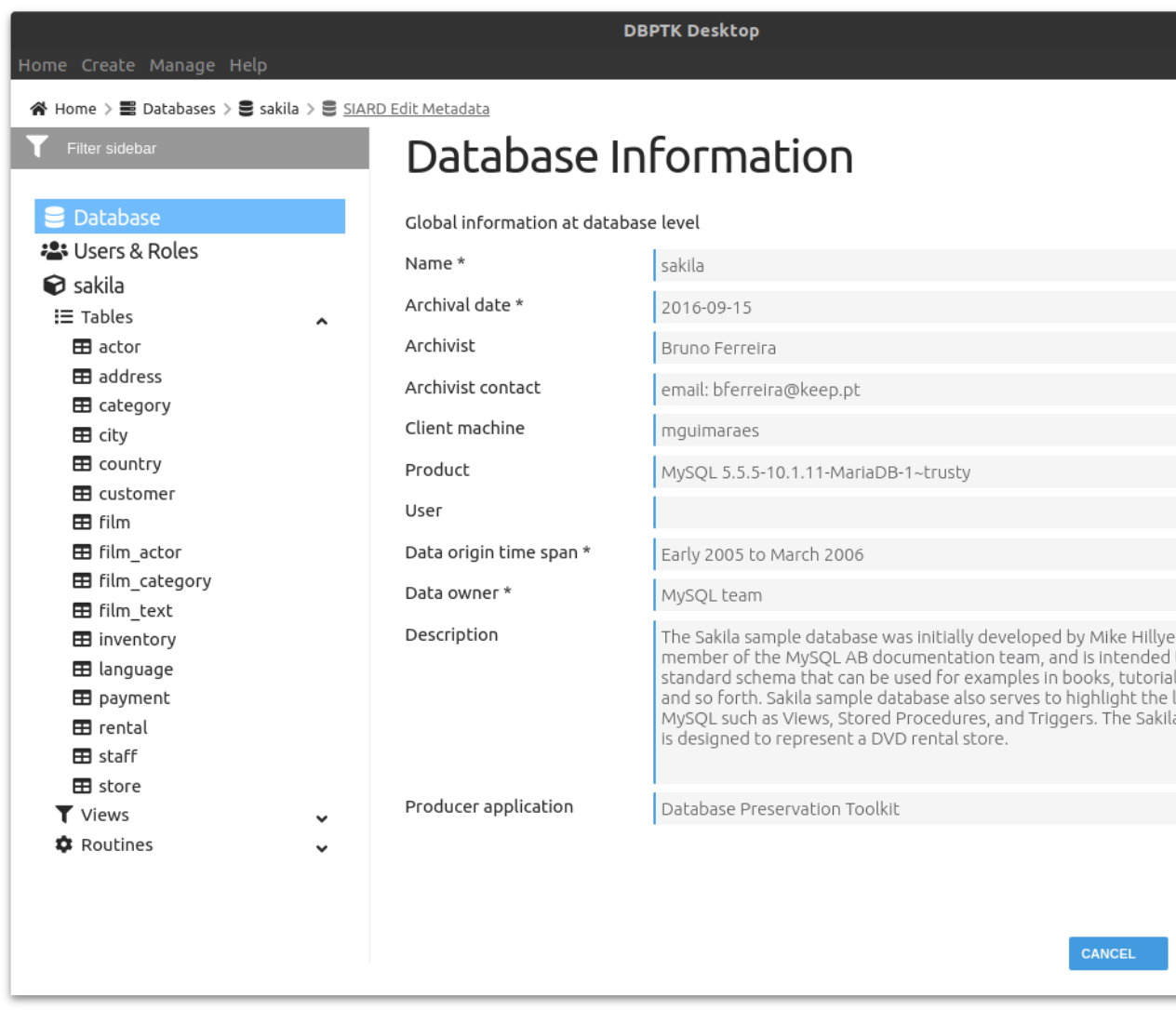
Add descriptions to database, tables and columns to better understand its contents.
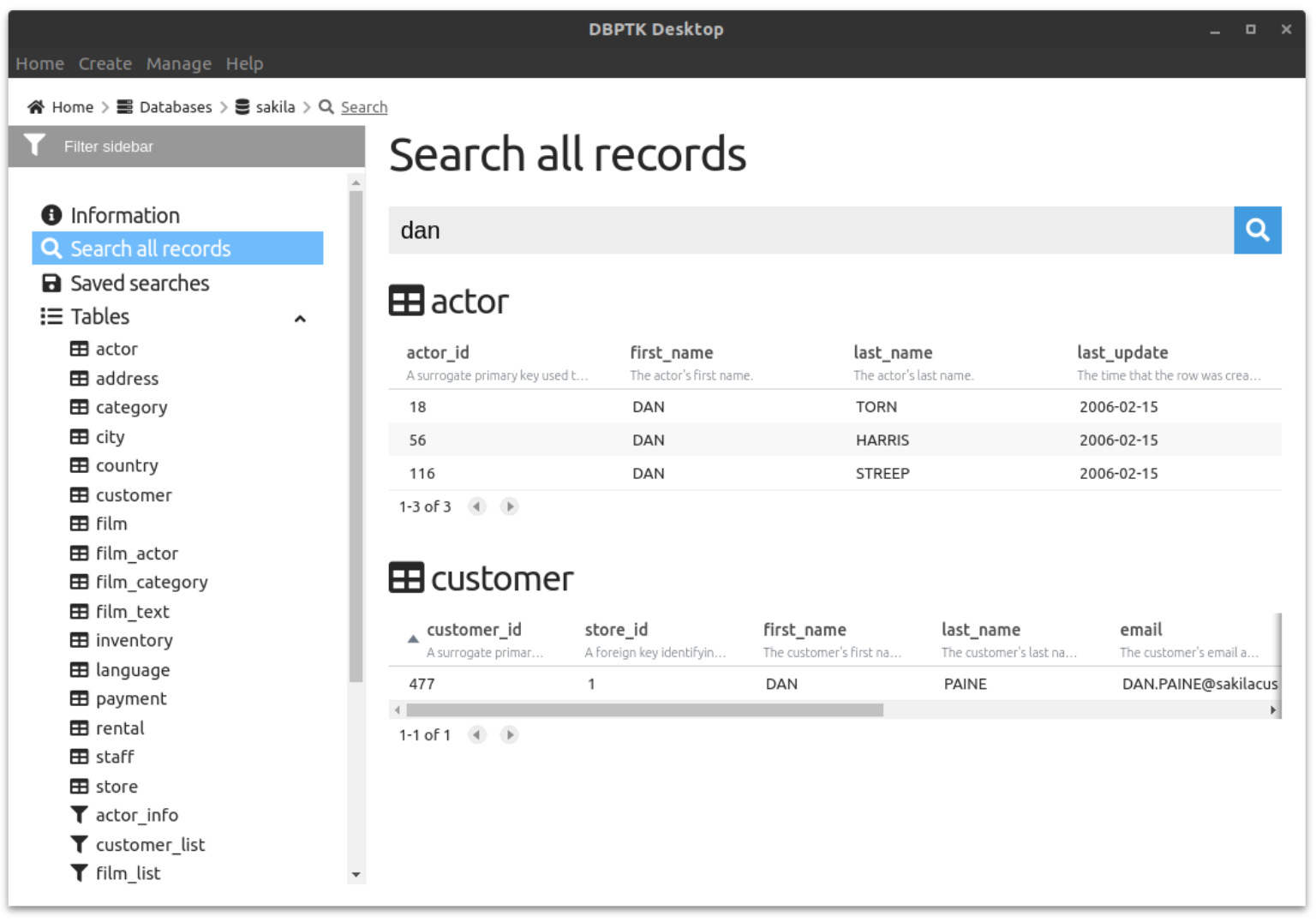
Google-like search on the entire database content.
Drill down on specific tables and filter for specific fields to find exactly what you are looking for.
Use the full query power of a modern database engine and enable advanced analytics like data mining.
Web application to browse and search the content of multiple large archived databases.
Read moreA web application that can be horizontally scaled to support many large-sized databases, accessed by hundreds of users simultaneaously.
Need help? Get support!

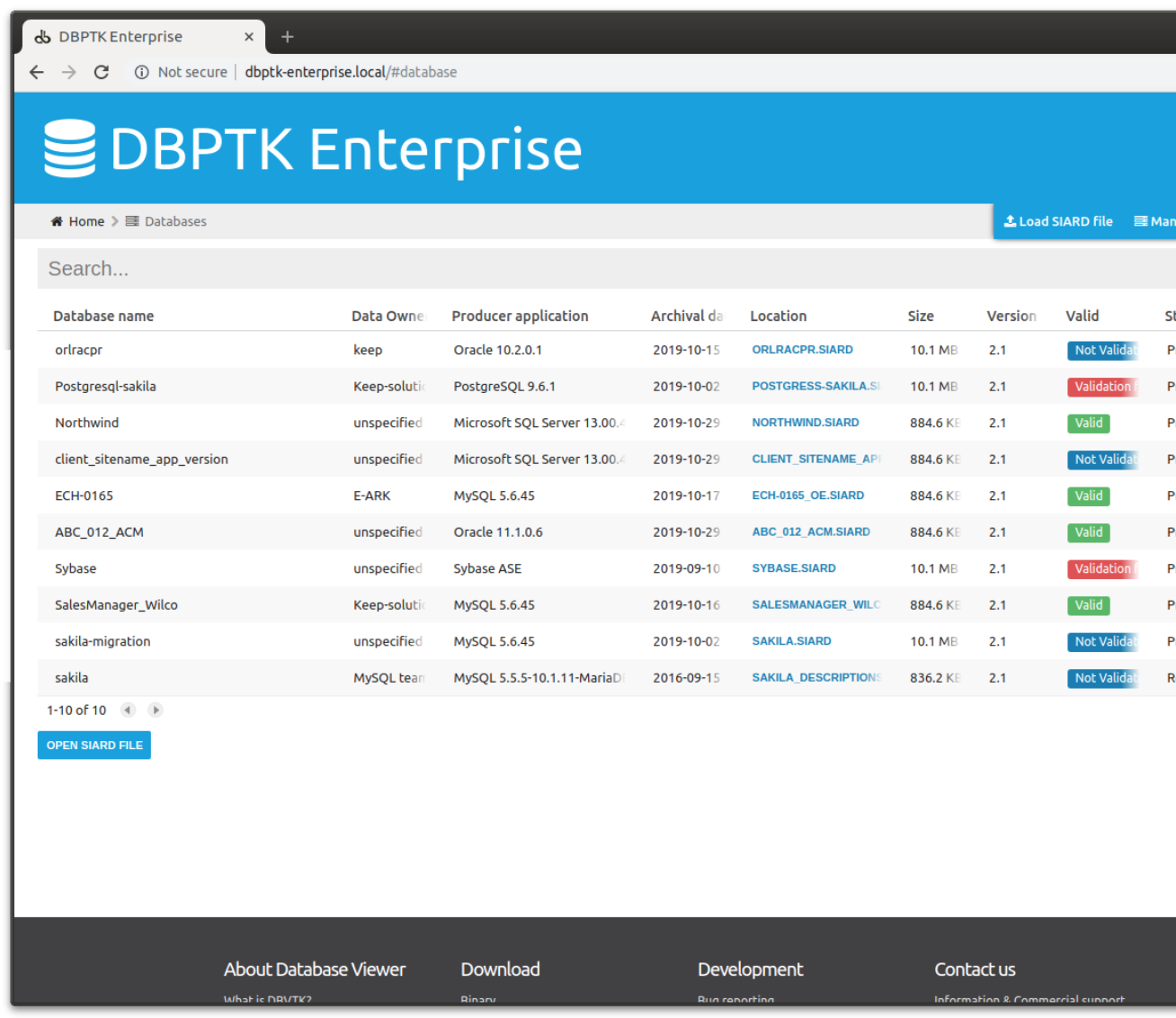
Search through the databases, manage their status, enrich their metadata, validate them, make them ready for your end users.
De-normalization and table/column hiding, to simplify browsing/search and allow anonymization of content.
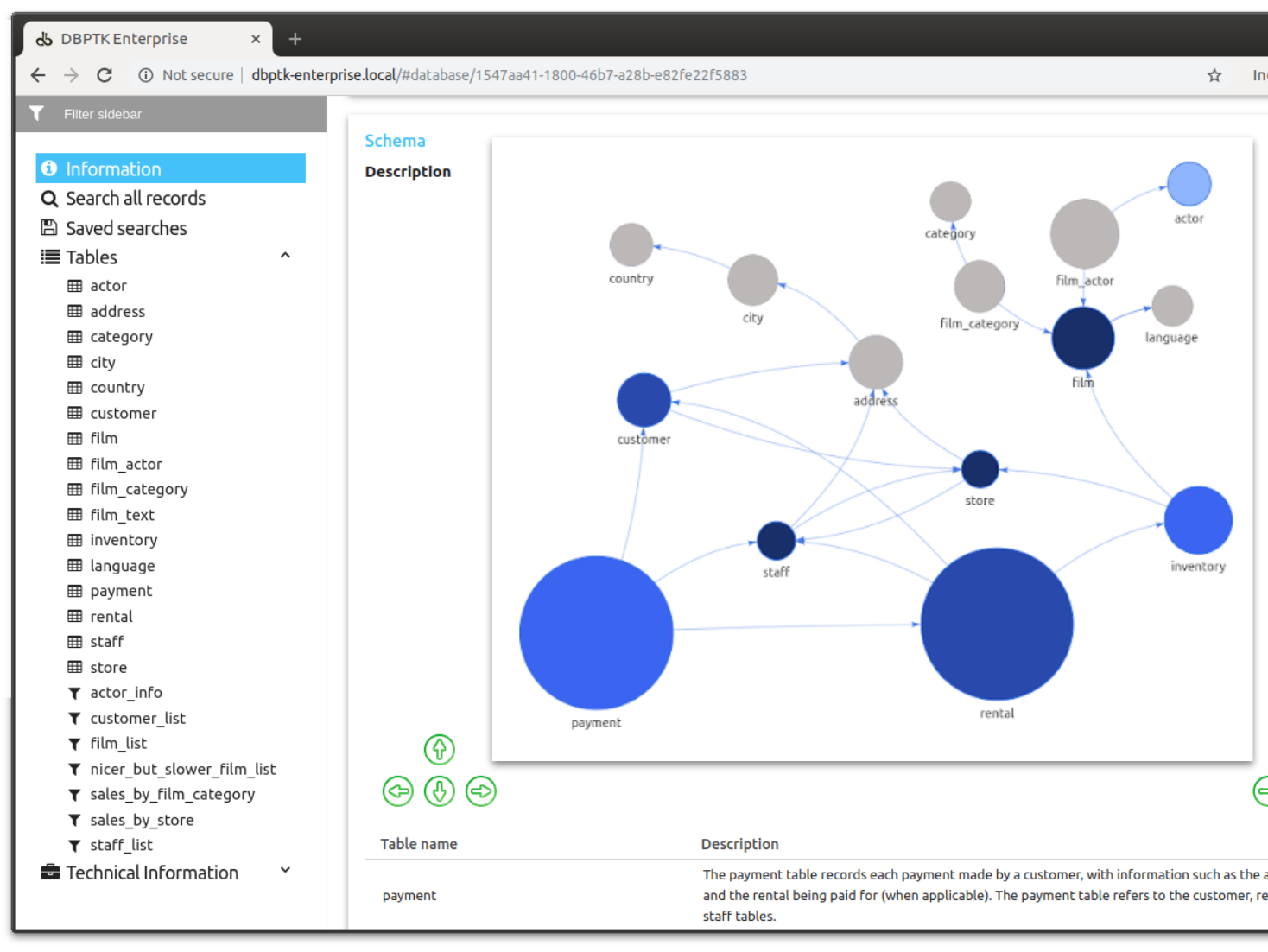

LDAP, Active Directory, Database, SAML, ADFS, OAuth2, OpenID, Google, Facebook, Twitter, FIDO U2F, YubiKey, Google Authenticator, Authy, etc.
Supports internal authorization definition or configurable external authorization.
Allow them to search on a prepared, de-normalized and anonymized database content.
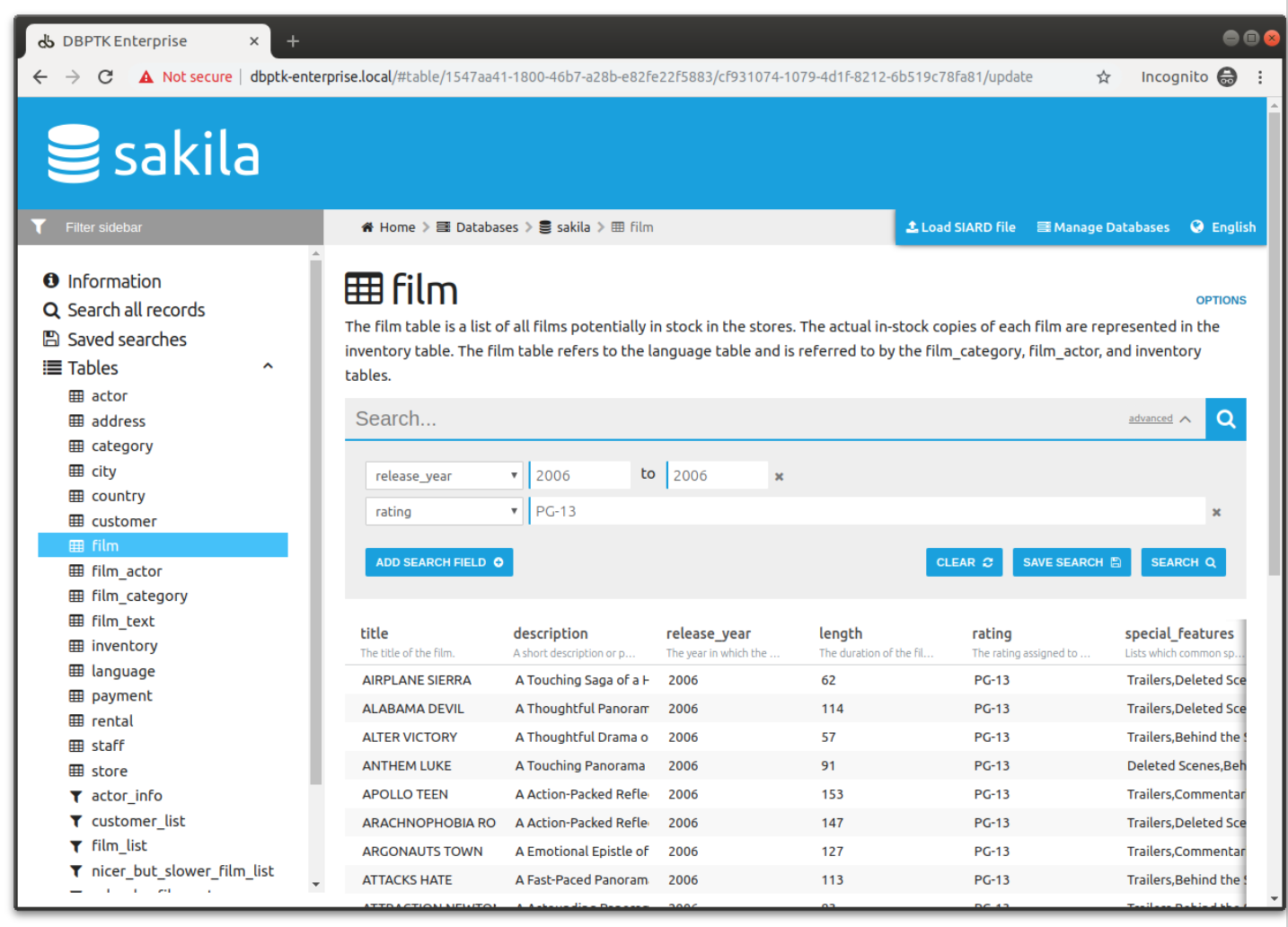
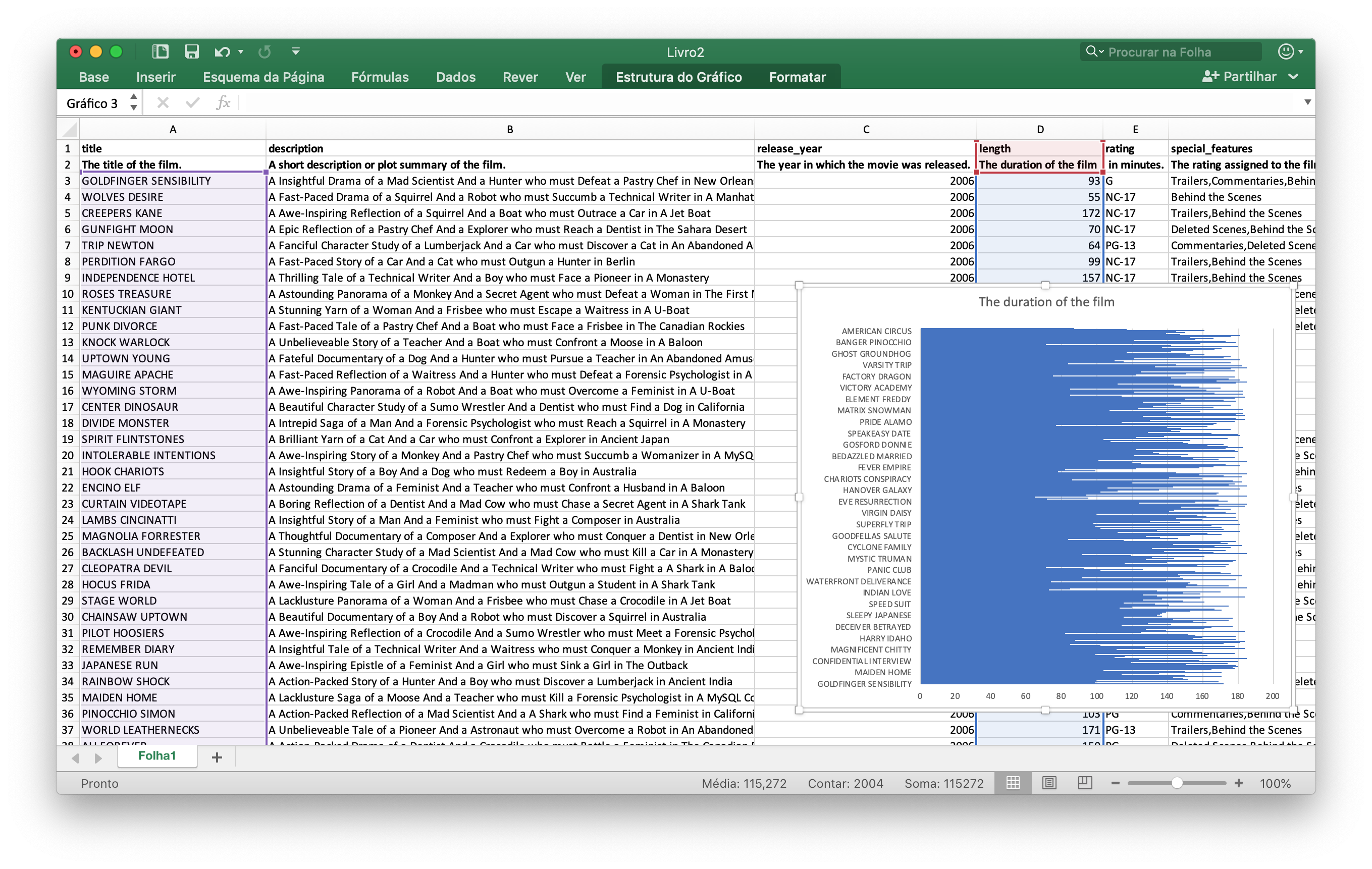
Allow users to save search results in Microsoft Excel or other spreadsheet software format for easy analytics and diagrams.
A command-line tool and development library for automation and systems integration.
Read moreCommand line interface allows easy automation of periodic tasks like saving database to archival format, validating, and editing metadata.
Library to allow integration of production systems to directly use database preservation features.
Code base that allows custom development of new features or specialized support for new or legacy database systems.
Need a new feature? Get support!